
Network problems rarely announce themselves. One slow app, a dropped call, or a frozen dashboard is often the first warning, and by then, users are already frustrated. That’s why smart organizations don’t wait for failures to happen. They actively watch, test, and improve their networks to keep work moving without disruption. Staying ahead of network performance issues is not just about speed; it’s about reliability, visibility, and quick action. In this blog, we’ll explore how organizations spot small signs before they turn into big problems, use the right tools to stay informed, and build networks that support growth instead of slowing it down.
Understanding the Strategic Difference in Network Approaches
Here’s where many IT teams trip up: they think watching their networks is the same as managing them. It’s not.

Network performance monitoring gives you eyes on what’s happening across your infrastructure right this second. Metrics get tracked. Alerts fire off. You know when things go sideways. Real-time visibility is crucial, sure, but it’s only your starting line.
Network performance management operates at a different altitude entirely. This is your strategic layer, wrapping monitoring into a full lifecycle that includes capacity planning, optimization, and decisions made before fires start. Management transforms raw data streams into intelligence that prevents issues rather than just spotting them. You need both running in tandem, monitoring acts as your sensory system, management serves as the brain deciding what actions matter.
Why Monitoring Alone Isn’t Enough
Plenty of companies lean entirely on monitoring and wonder why prevention fails. They can see problems crystal clear but lack the framework to stop them from happening again. A network monitoring tool can gather data around the clock, but that information often just accumulates unless you’ve got management processes converting insights into concrete action. PathSolutions’ TotalView bridges this gap by merging monitoring with automated root-cause analysis, shifting you from detection to genuine prevention.
The feedback loop connecting monitoring data with management decisions? That’s what determines success or failure in prevention strategy. Proper segmentation blocks that free rein, turning what could be an organization-wide meltdown into an isolated incident. Without containment like this, minor hiccups ripple across flat networks fast.
Building the Right Foundation
Early warning systems live or die by accurate performance baselines. You can’t spot abnormal behavior without first nailing down what normal looks like in your specific environment. Latency benchmarks, jitter tolerance, packet loss thresholds, throughput expectations, these vary wildly between different applications and user groups.
Dynamic baselines adjust to your network’s natural rhythms. Peak hours look different from 3 AM traffic patterns, and seasonal shifts change performance expectations. Static thresholds just generate alert fatigue. Intelligent multi-tier severity levels help your team zero in on what genuinely demands attention. Contextual alerting tied to business impact ensures critical issues get escalated immediately.
Network Performance Best Practices for Prevention-First Operations
Building a solid prevention framework begins with architecture and design choices. Redundancy strategies for critical pathways keep services operational even when individual pieces fail. Quality of Service policies guarantee business-critical apps get bandwidth priority when they need it most.
Design and Architecture Priorities
Segmentation for performance isolation stops problems in one corner from spreading organization-wide. This architectural decision pays off during security incidents and performance degradation equally. Configuration management and version control might feel tedious, but they’re lifesavers during issue resolution.
Quarterly performance audits catch slow-burn problems before they explode into emergencies. Change management protocols shouldn’t bottleneck progress, but they absolutely should prevent unforced errors. Pre-change impact assessments plus staged rollouts dramatically reduce the odds of widespread disruptions.
Maintenance That Actually Prevents Problems
Proactive maintenance schedules keep networks healthy. Firmware updates patch vulnerabilities and squash performance bugs, timing is everything though. Hardware lifecycle management ensures you’re not running mission-critical operations on equipment that’s one power surge away from failure. Even your cable infrastructure needs regular testing and certification.
A network monitoring tool can automate much of this routine work, keeping preventive cycles on track. These tools track device health, flag approaching end-of-life dates, and catch configuration drift that signals trouble ahead. Documentation standards aren’t exciting, but they’re gold when you’re troubleshooting at 3 AM on a Sunday.
Layer-by-Layer Prevention Strategies
Application layer problems love to disguise themselves as network issues. Application performance monitoring integration helps you distinguish actual network degradation from application bottlenecks. API gateway monitoring and throttling prevent runaway processes from devouring available bandwidth. Content delivery network optimization keeps customer-facing applications snappy.
Transport and Network Layer Focus
BGP routing optimization impacts performance across your entire infrastructure. MPLS and SD-WAN performance management demands different approaches than traditional WAN monitoring. IPv6 transition planning can’t be an afterthought, dual-stack environments need monitoring coverage for both protocols simultaneously.
Don’t ignore physical and data link layers. Switch and router health monitoring catches hardware failures before they trigger outages. Fiber optics and copper infrastructure both degrade over time, while wireless network optimization brings its own unique headaches.
Security’s Role in Performance
DDoS mitigation and traffic scrubbing protect availability, but they can introduce latency costs. Firewall performance impact monitoring ensures your security controls aren’t choking legitimate traffic. Zero-trust architecture performance considerations matter because microsegmentation adds overhead requiring active management.
The AT&T breach affecting both past and present customers showed the real price of connecting multiple data stores without adequate controls, attackers found a goldmine of personal data in one sweep. Security lapses like this create performance nightmares when teams scramble to implement emergency patches.
Selecting and Implementing the Right Tools
Modern network monitoring tools need multi-vendor and multi-cloud support baked in. API-first architectures enable integration with your existing ITSM and collaboration platforms. The synthetic versus real-user monitoring debate depends entirely on what you’re measuring. Agent-based monitoring provides deeper visibility, while agentless approaches simplify deployment.
Full-stack observability platforms offer comprehensive coverage, though specialized tools sometimes excel at specific tasks. Flow analysis and NetFlow collectors surface traffic insights other tools miss entirely. Packet capture and deep packet inspection help with detailed troubleshooting, though they’re impractical for continuous monitoring at scale.
Implementation Approaches
Phased deployment minimizes risk and lets you learn from early stages. Integration with collaboration tools enables ChatOps approaches that accelerate response times. Training and adoption strategies determine whether your team actually uses what you’ve deployed, or lets it collect dust.
Measuring your monitoring tool effectiveness closes the loop. Are false positives dropping? Is mean time for detection shrinking? These metrics prove ROI and guide optimization.
Multi-Cloud Complexity and Solutions
Cloud environments create visibility gaps that traditional monitoring doesn’t handle. IaaS, PaaS, and SaaS environments each bring unique challenges. Multi-cloud performance benchmarking helps verify cloud providers actually meet their SLA promises.
SD-WAN transforms network performance management by enabling application-aware routing policies. WAN optimization techniques and branch office performance management demand fresh approaches. Edge computing and IoT networks push monitoring to distributed architectures where low-latency requirements mean tracking edge device performance becomes critical.
Prevention Strategy Comparison
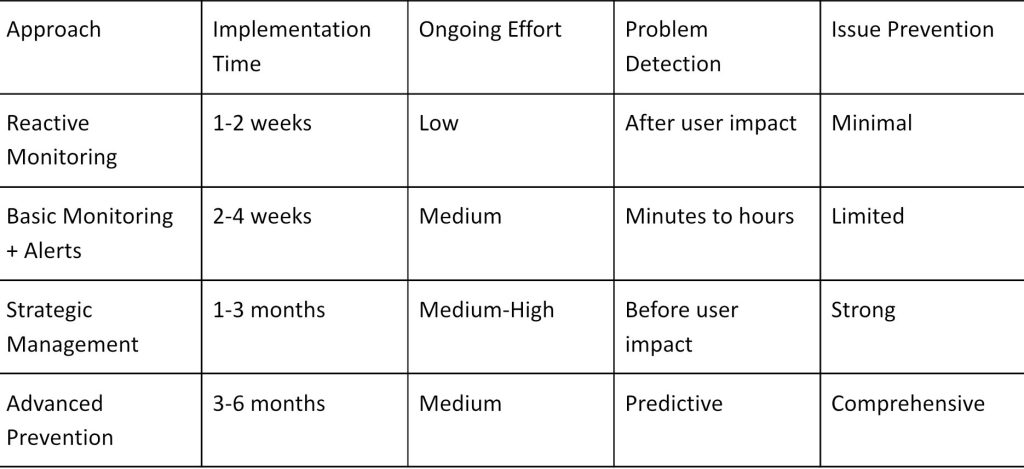
This comparison illustrates why how to prevent network issues requires moving past basic monitoring. Strategic management takes longer to spin up but delivers substantially better results.
Building the Right Team and Processes
Network reliability engineers apply SRE principles to network operations. Data analysts spot performance trends that predict future troubles. Automation engineers build orchestration that handles issues without requiring human intervention.
Standard operating procedures for common scenarios reduce response times. Automated remediation playbooks tackle routine problems while teams focus on complex challenges. Incident post-mortems and continuous improvement cycles prevent identical issues from recurring.
Common Questions About Network Performance Prevention
What’s the difference between monitoring and observability?
Observability extends monitoring by adding deeper context about system behavior and relationships. Traditional monitoring answers “what broke,” while observability answers “why it broke and what ripple effects happened.” You need observability when wrestling with complex, distributed systems where simple metrics don’t tell the complete story.
How often should performance baselines be updated?
Review baselines monthly for dynamic environments, quarterly for stable ones. Automated baseline adjustment systems respond to changes continuously. Seasonal business cycles and growth patterns both shift what “normal” looks like, requiring regular recalibration to keep alerting thresholds accurate.
Can small businesses implement enterprise prevention strategies?
Absolutely, the approach just differs. Start with cloud-based monitoring services that scale alongside your needs. Focus on highest-impact prevention practices first. Many modern tools offer affordable entry points, and phased implementation spreads costs over time while delivering incremental value at each stage.
Final Thoughts on Staying Ahead
Prevention-first approaches deliver competitive advantages that reactive strategies can’t touch. Organizations implementing these frameworks experience fewer disruptions, reduced operational costs, and significantly better user satisfaction.
The winning formula combines monitoring visibility with management decision-making, backed by tools that automate detection and response. Start with a focused 90-day implementation plan establishing baselines, deploying monitoring, and building team capabilities. Long-term network excellence emerges from continuous improvement, not one-time fixes.
The real question isn’t whether you can afford to prevent network issues. It’s whether you can afford not to.



